AI is no longer just a technology investment – it’s a new kind of variable cost. And it is not same as the software licenses and server bills.
A New Unit of Consumption
Every time someone sends a message to an AI assistant, asks a model to summarize a document, or triggers an autonomous agent to complete a task, something invisible happens: text gets broken into small numerical fragments called tokens. A token is roughly 3–4 characters of English text. The phrase “AI drives innovation” becomes four tokens. A 1,500-word report becomes around 2,000 tokens.
This matters because every token has a price. You’re billed for the tokens your prompt sends in (input tokens), and again for the tokens the model generates back (output tokens). At a single-interaction level, this cost is negligible. At organizational scale millions of users, hundreds of workflows, agentic systems reasoning through multi-step tasks, the token meter runs fast.
Google processed 480 trillion tokens per month across its products and APIs in 2025, a 50× increase from the year prior. One Seattle-based startup consumed nearly a billion tokens in 30 days.
Tokens are the new unit of AI cost. Understanding how they work is no longer optional.
How Tokenization Actually Works
When a user types a message into an AI-powered application, the text doesn’t travel to the model as plain language. Instead, a component called a tokenizer breaks it into a sequence of numerical IDs that the model can process.
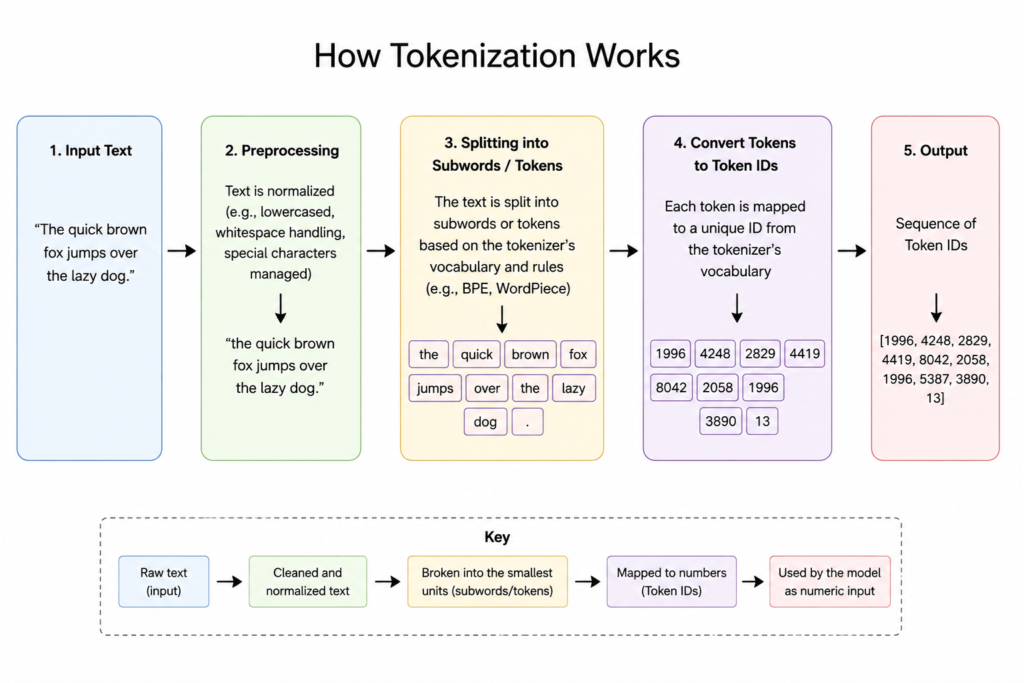
Short common words often map to a single token. Longer or rarer words get split. “Darkness” becomes “dark” + “ness” – two tokens, each with a unique numerical ID. Crucially, the shared suffix “ness” helps the model learn that “darkness” and “brightness” are structurally related, even before it understands their meaning.
This same logic extends beyond text. Visual AI models tokenize pixels and voxels. Audio models turn sound clips into spectrograms – visual representations of sound that can be processed like images. Multimodal models do all of this simultaneously, often at a significant token premium.
Why Traditional Cost Models Break Down
Token costs are usage-driven, nonlinear, and highly variable. They scale not just with the number of users, but with how those users interact – the length of their prompts, the depth of context carried into each conversation, the complexity of the model invoked, and whether autonomous agents are making dozens of tool calls behind the scenes.
Many organizations are currently insulated from direct token costs because AI is bundled into SaaS tools and enterprise platforms. Providers are shifting toward usage-based and outcome-based pricing models as agentic capabilities mature. The variable cost is coming, and most organizations aren’t ready to measure it.
The Three Deployment Models
Not all token costs are created equal. The price per million tokens shifts dramatically depending on how you deploy AI infrastructure – and the right answer depends entirely on your scale.
Cloud APIs (the default for most organizations) offer flexibility and zero upfront capital. Unit costs are higher, but at low to moderate volumes, the convenience premium is worth it.
Cloud providers – alternative cloud infrastructure built specifically for AI workloads – become cost-competitive at roughly 49 billion annual tokens. The pricing curve crosses below the standard API cost at that threshold.
Self-hosted – purpose-built data center infrastructure for high-volume inference – require significant upfront capital but offer the lowest unit cost at sustained scale.
The Real Cost Drivers: Five things we should understand
Token billing is only the starting point. Actual costs emerge from a set of interacting variables:
1. Output pricing asymmetry. Most providers charge more for output tokens than input tokens. This creates a direct incentive to design prompts that elicit focused, concise responses rather than verbose elaborations. A model generating a 2,000-word summary when 300 words would do is an engineering problem with a financial consequence.
2. Model tier selection. LLM providers offer models ranging from lightweight economy tiers to high-capability premium models. Routing a simple FAQ lookup to a frontier reasoning model is the equivalent of booking a private jet for a short commute. Matching task complexity to model capability is one of the highest-leverage cost levers available.
3. Context length accumulation. Maintaining conversational context is expensive. Every message in a multi-turn conversation gets passed back to the model as input context, so longer conversations consume exponentially more tokens. Effective context compression – periodically summarizing conversation history rather than appending indefinitely – can meaningfully reduce cost without degrading response quality.
4. Agentic and RAG overhead. Retrieval-Augmented Generation (RAG) systems and agent-based architectures introduce “hidden” token costs: embedding indexing, retrieval queries, tool calls, and inter-agent communication all consume tokens beyond what the final user-facing response requires. These often go unmeasured until they appear as an unexplained spike on an infrastructure bill.
5. Governance gaps. Without team-level and feature-level tracking, there’s no way to know which parts of an organization are driving token consumption. A single engineering team experimenting with an agentic workflow during a hackathon can generate as many tokens as a stable production feature serving thousands of users – and without visibility, both appear as the same undifferentiated cloud bill.
The transition from “AI is exciting” to “AI is expensive if we’re not careful” is already underway for large-scale adopters. It will arrive for everyone else within the next few years.